이전에 신경망들은 데이터를 구성하고 있는 특징들을 고려하지 않았다. 데이터들의 차원은 독립적이라고 보았다. 시각적으로 다르게 인식할 수 있는 패턴임에도 신경망 알고리즘에서는 구분하지 않았다. 영상 데이터 표현은 인간의 시작 정보 체계를 신경망에 반영하고 있지 않았다. 즉, 위치 정보가 중요한 다차원 데이터 표현방법이 필요했다.
해결방법은 주변 특정 정보를 포함한 표현 혹인 인코딩 방법이 필요하다.
위치 정보를 고려하지 않게되면 점에서의 y값이 같기 때문에 구분할 수 없다. 반대로 특징 간 위치 정보를 포함해서 인코딩을 한 경우 왼쪽과 오른쪽 같을 보면서 특성을 파악하고 구분할 수 있다. 이렇게 주변 정보를 활용할 경우 인식률이 높힐 수 있다.
영상도 동일하다.픽셀값이 같으면 구분을 할 수 없지만 주변 정보 포함시키면 특징이 구분이 된다.
영상을 효과적으로 인코딩 하는 방법
주변의 특징 정보를 추가해서 데이터의 특징 차원을 늘린다.문제점 : 특징 수가 증가하면 신경망의 크기가 증가되고 최적화된 학습 결과를 얻기 어려워짐
해결 방안 :
- 한개의 특징에 주변 정보를 포함해서 정의 : 주변 정보의 평균값 (한점을 중심으로 주변 값을 다 더하고 9로 나누면 평균을 얻음밝기 정보를 알 수 있음위아래의 차가 양수일 경우 위에있는 색이 밝고 아래 있는 색이 어두운 것을 의미 → 주변 밝기 정보를 포함)
- 한개의 특징에 주변 정보를 포함해서 정의 : 뺄셈 연산 사용
특징
- 음수일 경우 위는 어둡고 아래는 밝다는 것을 의미
- 평균을 전체가 아닌 상하좌우 4개만 사용하거나 수직 2개만 사용도 가능
- 특징의 수를 유지하면서 같은 밝기 값을 갖는데 주변의 밝기 정보에 따라 값이 다르게 나옴.
- 충분한 양의 데이터 확보의 어려움이 발생하여 인식률 저하를 발생시킴
- 저차원을 고차원으로 늘리면 주변 정보를 고려했기 때문에 문제 해결 가능
2D 컨볼루션 : 주변 정보를 인코딩 하는 방법
입력영상과 컨볼루션 필터를 픽셀바이 픽셀로 곱해서 다 더하는 것을 컴벌루션이라고 한다.
평균을 이용한 주변 정보 인코딩은 전체 데이터가 가중치 1/9로 구성된 행렬을 사용해 표현할 수 있다. 컴볼루션을 사용하여 3*3 마스크를 하나 계산하고 각각의 크기는 1/9로 들어가 있다. 이 방법은 평균을 구하는 방법과 동일하다
밝기 차이를 인코딩 하는 필터는 +1, -1 를 주고 나머지는 0을 준다. 위에서 아래를 뺀 형태가 된다.
결국 핵심은 마스크 필터를 어떻게 설계하느냐인데 이것에 따라 input영상의 특성을 파악할 수 있다.
컨볼루션을 이용하면 특징을 검출할 수 있다.
다수의 필터를 정의하면 입력 영상의 기하학적 특징을 파악할 수 있다. (생물학적 구조와 유사)
- 평균 컨볼루션 필터 : 형상을 흐리게 하거나 단순 노이즈 제거
- 엣지 컨볼루션 필터 : 수평 및 수직 엣지 검출에 유용
- 샤프닝 컨볼루션 필터 : 밝기의 경계 영역에서 값이 커짐
영상을 위한 컨볼루션 필터 설계는 어렵다. 이유는 영상의 기하학적 변화에도 강인하도록 필터가 설계되어야 하기 때문이다. (크기, 각도, 밝기, 위치)
필터 수가 많아지면 차원 수가 늘어나 계산 복잡도가 급격히 높아진다.
CNN 이전 방법 : 모든 필터를 모아놓고 가장 적절한 필터를 찾아 인식기에 넣는 과정, 적절한 필터를 찾을 경우 전문가가 필요
CNN 이후 방법 : 필터를 찾기 말고 이것을 신경망을 통해 학습 시켜서 찾자
컨볼루션 신경망이란?
문체의 방향과 크기가 바뀌어도 어려움 없이 물체를 인식할 수 있다는 생물학적 근거에 기반
이미지로부터 직접 공간적 특징을 학습
일반적으로 다층의 필터로 구성 (low-level filter-방향 밝기 특징 엣지 , mid-level filter - 컴포넌트 눈 코 입술 등의 특징, high-level filter - 풀고자 하는 필터)
<과정>
영상 자체 → 2D신경망 구축 → 필터학습 (컨볼루션 마스크) → 신경망 기반 분류
<컨벌루션 신경망 구조>
컨볼루션 계층, 풀링 계층, 기존 신경망을 통해 이미지 분류
입력 이미지 → 컨볼루션 계층 (다양한 컨볼루션 마스크 학습) → <풀링계층 (이미지의 크기를 축소하는 레이어)>여러번 실행 가능 → 다층신경망 계층
<컨볼루션 계층>
입력 영상이 3232로 주어지면 필터의 값은 초기에 랜덤하게 생성된다. 필터의 크기는 33, 5*5가 될 수 있다. 필터가 6개가 적용이 된다면 실제 출력되는 결과물은 (32,32,6)이 된다. 이를 특징 맵이라고 한다.
<필터 연산 시 외각 픽셀 처리>
가장 자리 픽셀들은 이웃하는 픽셀 정보가 없기 때문에 컨볼루션 연산을 수행 할 수 없다.
따라서 컨볼루션 계층을 여러번 거쳐도 영상의 크기를 유지할 수 있는 방법이 필요하다.
가장 밖에 있는 픽셀들은 주변에 점이 존재하지 않기 때문에 계산에서 제외가 된다. 그렇게 되면 55 영상이 33으로 줄게된다.
이를 해결하기위해 패딩과 스트라이드를 사용한다.
- 패딩 : 데이터의 외부에 일정한 값의 계층을 덧대는 것 → 입력 영상의 가장자리에 0으로 padding 수행마스크가 33 이면 패딩1, 55면 패딩 2, 7*7은 패딩 3 이렇게 적용시켜준다.p : 패딩
- n : 입력 영상의 크기
- 출력 영상의 크기 = (2p+n) * (2p + n)이다. 이를 다시 컨볼루션하게 되면 n*n이 나오게 된다.
- 패딩 수행 시 여러 번의 컨볼루션 계층을 사용해 신경망을 구성해도 영상의 크기가 줄어들지 않는다.
- 스트라이드 : 컨볼루션 연산 시 이동하는 x방향과 y방향의 이동량 (보폭) → 일반적으로 1을 사용 1일 경우 동일한 크기의 결과가 나오지면 2일 경우 원래 영상이 반으로 줄어든게 된다.
<풀링 계층>
풀링 계층 : 입력 영상의 크기를 줄이는 역할 (대략적인 정보 특성만 남김)
영상의 크기를 반감해 계산량을 줄이고, 데이터에서 치중된 과적합 방지
필터는 학습해야할 가중치 이다. 영상이 크면 가중치를 구해야하는 미지수가 많게 되는데, 미지수가 많은데 train 데이터가 얼마 없으면 과적합 문제가 발생한다. 과적합 문제를 줄이기 위해서 영상의 크기를 줄여야한다.
풀링 방법
- Max Pooling: 영상의 크기를 줄이는 방법 중 일반적으로 최대 풀링을 활용함
- Average Pooling : 전체 데이터 중 평균값으로 대체
<기존 신경망을 통해 이미지 분류 - 기존 다층 신경망>
Max Pooling을 하게되면 출력된 결과가 2D 이미지가 된다.
플래튼 ? 다층 신경망 계층으로 넘겨줄 때 이전 계층의 2차원 형태의 데이터를 1차원 형태로 변환
<컨볼루션 신경망 정리>
컨볼루션 계층과 Max Pooling 계층으로 묶어진 과정은 반복될 수 있음(특징 추출 레이어
input이 주어지면 필터들로 이뤄진 컨볼루션연산을 수행한다. 필터 수만큼의 결과가 나오면 영상의 크기를 줄이기 위해서 MaxPooling과정을 거치고 이 과정을 반복한다. 이 부분을 특징 축소라고한다. 전체 과정을 특징 추출 레이어라고 한다.
2D영상 이미지가 나오면 이것을 1차원으로 변환한다.
만들어진 특징을 기존 분류기에 넣어 입력, 히든 유닛, 출력층을 거쳐 신경망을 만들 수 있다.
25개 및 59개의 필터 역시 동시에 역전파 오류법을 통해 학습
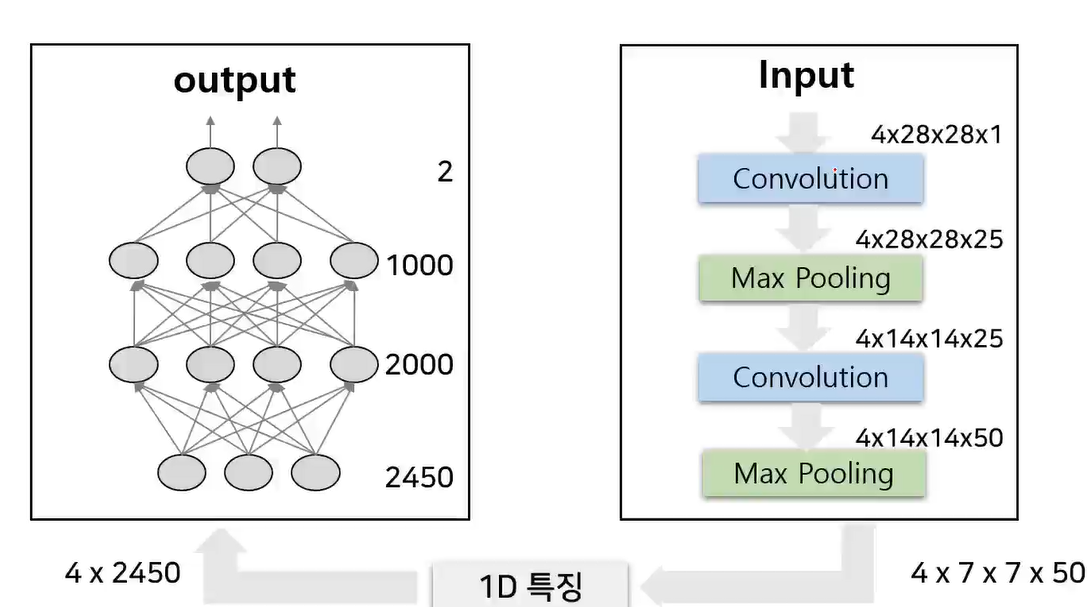
입력 영상 4개가 주어지고 영상 크기를 28*28 흑백 영상이라고 가정
첫번째 컨볼루션이 25개 필터의 수를 사용한다고 가정하였기 때문에 42828*25 (4차원 데이터)
Max Pooling을 통해서 그대로 유지되면서 이미지의 크기만 반으로 줄인다. 41414*25
그리고 다시 컨볼루션 필터 50개를 사용하면 41414*50이 된다.
Max Pooling을 통해서 그대로 유지되면서 이미지의 크기만 반으로 줄인다. 477*50
신경망을 연결하기 위해 1차원으로 바꾸면
샘플수 4개는 유지하면서 7750 = 2450 이 된다.
입력 영상이 층을 통과하게 되면 2450차원의 데이터 형태로 만들어 지게 된다.
신경망 입장에서는 2450이 인풋 데이터의 크기, 히든 유닛, 출력 결과 노드 수, → out 이렇게 된다.
'Other > Computer vision' 카테고리의 다른 글
| [CV] ImageNet을 이용한 인식 (0) | 2021.12.17 |
|---|---|
| [CV] CNN 활용한 영상 인식 (0) | 2021.12.17 |
| [CV] 전이 학습 (0) | 2021.12.17 |
| [CV] 객체 검출, YOLO (0) | 2021.12.06 |
| [CV] 전이학습 Freeze, Fine:Tunning (0) | 2021.12.06 |
