전이 학습이란?
다른 곳에서 학습된 결과를 재 사용하는 방법
Freeze란?
얼린다는 의미
즉, 학습이 불가능하도록 얼린다는 의미이다.
VGG16는 매우 오랜 시간 동안 학습하기 위해 train이 되었다.
CNN은 특징 추출과 특징 분류로 구성되어있다. Freeze 시키는 것은 일단 VGG16로 학습을 시킨다. 그리고 분류기 부분만 새롭게 학습을 한다.
이전에는 CNN으로 계층을 만들고 필터링을 통해 필터링 후 뒤에다가 일반 신경망을 붙이는 것이었는데 시간이 오래 걸리고 네트워크 크기가 굉장히 커지게 된다. (이미지 크기가 크기 때문)
vgg_conv = VGG16(weights='imagenet', include_top=False, input_shape=(image_size, image_size, 3))
// 필터링을 거치고
vgg_conv.summary()
for layer in vgg_conv.layers[:]:
layer.trainable = False
for layer in vgg_conv.layers:
print(layer, layer.trainable)
model = Sequential()
model.add(vgg_conv)
//Sequential을 add 한다. 기존 네트워크를 사용할 수 있는 부분
model.add(Flatten()) //1차원을 바꾸고
model.add(Dense(1024, activation='relu')) //히든 은닉층을 추가한다.
model.add(Dense(1, activation='sigmoid'))
model.compile(optimizer='adam',
loss='binary_crossentropy', metrics=['accuracy'])
model.summary()
기존의 신경망을 사용한다. (다시 학습하는 것은 아님)
여기서 주요하게 봐야 할 코드가 있다!
include_top 이란?( false로 할 경우 별도의 파일이라서 다운을 받아야 한다!)
vgg_conv = VGG16(weights='imagenet', include_top=False, input_shape=(image_size, image_size, 3))
include_top을 false로 할 경우 특징 추출기까지만 구성되어 있는 weight를 가지고 있다.
이때, 최종 층이 MaxPooling2D까지여서 Flatten, 은닉층, 출력층 이렇게 설정해줘야 한다.
이렇게 네트워크를 구성할 경우 CNN이다. 하지만 여기서 레이어를 조사하면서 각각의 layer.trainable = False로 바꾼다면, 각 레이어의 파라미터들은 학습이 안되고 고정이 된 상태가 된다.
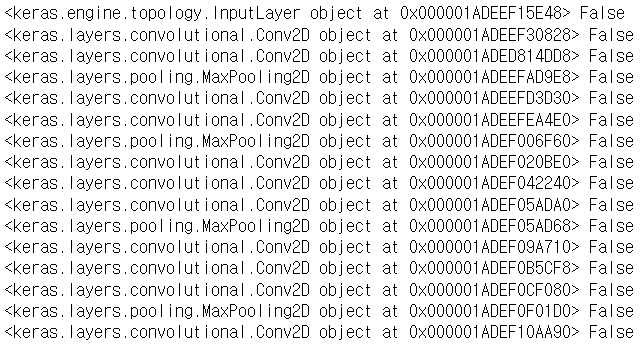
위 사진은 print(layer, layer.trainable) 결과이다.
따라서 weight가 고정이 되기 때문에 학습된 weight만 사용할 수 있게 된다.
(잘 학습된 필터는 그대로 사용)

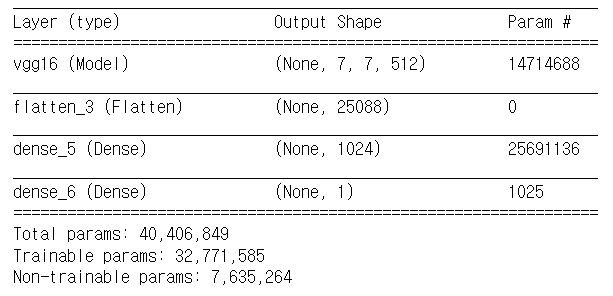
summary를 살펴보면 vgg경우 파라미터가 14714688개
dense_3은 25691136
deense_4는 1025개가 있다.
총 파라미터 수는 40406849개이지만 학습 가능한 파라미터는 25692161개가 된다.
vgg는 학습할 필요가 없기 때문!
따라서 깊은 네트워크를 가지고 있지만 학습시켜야 하는 파라미터는 상당히 줄어들게 된다!
Fine:Tunning란?
모든 층을 freeze 시키는 것이 아닌, 특정 부부만 제외하고 freeze
vgg_conv = VGG16(weights='imagenet', include_top=False, input_shape=(image_size, image_size, 3))
//특징 추출기만 사용
//모든 층을 freeze시키는 것이 아닌, 앞에 부분에서 4 부분만 제외하고 학습 시킴
for layer in vgg_conv.layers[:-4]:
layer.trainable = False
# Check the trainable status of the individual layers
for layer in vgg_conv.layers:
print(layer, layer.trainable)
from keras import models
from keras import layers
from keras import optimizers
# Create the model
model = models.Sequential()
# Add the vgg convolutional base model
model.add(vgg_conv)
# Add new layers
model.add(layers.Flatten())
model.add(layers.Dense(1024, activation='relu'))
model.add(Dense(1, activation='sigmoid'))
model.compile(optimizer='adam',
loss='binary_crossentropy', metrics=['accuracy'])
model.summary()
Freeze와 Fine:Tunning의 차이점❓
기본적으로 깊은 네트워크를 설계할 때 낮은 층에서는 밝기나 방향에서 민감하게 학습이 되고 상위 단계로 갈수록 풀고자 하는 방향성으로 학습이 된다.
그렇다면
우리가 풀고자 하는 학습 방향성은 상위 단계에서 학습이 된다.
따라서 Fine:Tunning 은 최상위에 있는 분류기들은 다시 학습을 한다.
학습시켜야 하는 파라미터는 더 많아지게 되겠지만, 우리가 풀고자 하는 학습 방향이 다시 학습이 된다!
summary를 보게 되면 학습해야 할 파라미터가 추가되어서 늘어난 것을 볼 수 있다.
model.fit_generator(train_generator, epochs=1)
scores = model.evaluate_generator(test_generator)
print("%s: %.2f%%" %(model.metrics_names[1], scores[1]*100))
학습과 테스트는 둘 다 동일하다!
높은 학습 성능이 나타나는 것을 확인할 수 있다. 효과적으로 깊은 CNN 구성 가능!
추가로 VGG16의 경우 Flatten 과정을 거쳤다. 하지만 조금 더 효율적으로 하기 위해 GlobalAveragePooling2D를 사용했다.
model.add(GlobalAveragePooling2D())
model.add(Dense(1024, activation='relu'))
model.add(Dense(11, activation='softmax'))
만약 Flatten 시 특징 추출의 개수가 크게 계산돼 은닉층의 갯수가 매우 커지게 된다.
GlobalAveragePooling2D는 Flatten 하지 않고 그냥 합치는 것으로 영상이 하나의 픽셀로 평균화된다.
이로 인해 학습해야 하는 파라미터의 개수가 크게 줄어들게 된다!
'Other > Computer vision' 카테고리의 다른 글
| [CV] ImageNet을 이용한 인식 (0) | 2021.12.17 |
|---|---|
| [CV] CNN 활용한 영상 인식 (0) | 2021.12.17 |
| [CV] 사람의 시각을 닮은 신경망 CNN (0) | 2021.12.17 |
| [CV] 전이 학습 (0) | 2021.12.17 |
| [CV] 객체 검출, YOLO (0) | 2021.12.06 |
